computer vision 의 가장 대표적인 task 중 하나인 Image classification!
내가 이해하고 있는 classification에 대해 설명해보려고 한다.
나는 개별적인 이론을 이해하는 것이 어렵진 않았지만, 전체적인 흐름과 실질적인 모델의 학습 원리를 뒤늦게 깨우쳤기에...
딥러닝 모델이 어떻게 작동하는지를 중심으로 설명하고자 한다!
Image Classification 이란?
Image Classification(이미지 분류)는 computer vision task중 하나로, 이미지 내용을 기반으로 이미지를 분류하고 레이블을 지정하는 과정을 말한다.
가장 쉬운 예시를 들자면,
강아지와 고양이를 분류하는 문제에서 아래의 이미지가 둘 중 무엇인지를 판별하는 것이다.

물론, 위의 예시는 단순히 강아지와 고양이를 분류하는 문제로 정의했지만 데이터셋이나 문제 정의에 따라 동물 종류 분류/사자와 호랑이 분류 등 다양하게 확장될 수 있다.
그렇다면 문제 정의는 어떻게 하는 것인가?
문제 정의
문제 정의 자체는 하기 나름이다.
강아지와 고양이 중 하나만 알고 싶다면 → 강아지/고양이 분류
10종류 동물 각각을 분류하고 싶다면 → 10가지 카테고리 동물 분류
사람과 동물을 분류하고 싶다면 → 사람/동물 분류
등등 다양하게 정의할 수 있다.
하지만 어떻게 정의하냐에 따라 필요한 데이터가 달라진다!
데이터 준비
ex 1) 강아지/고양이 분류
이 문제에서 우리는 여러 종류의 강아지 이미지, 여러 종류의 고양이 이미지가 필요하다.
뿐 만 아니라 label이 있는 파일이 필요하다.
우리는 두 종류만 분류하고 싶기 때문에 강아지/고양이 2 개의 class를 다룬다.
[class label]
강아지: 0
고양이: 1
이렇게 각각의 동물이름을 인공지능이 이해할 수 있는 숫자로 바꾸는 과정을 labeling 이라고 한다.
모델 학습을 위해서는 명시적인 label이 필요한 것이다.
대표적인 데이터셋인 ImageNet dataset이다.
설명을 보면 약 1400만개의 이미지가 존재하고, 1000개의 class를 가지고있다.
여기서 1000개의 class는 annotation 파일로 존재하는데 이 파일로 이미지와 class가 매칭된다.
만약 여기서 강아지/고양이 분류를 위한 데이터를 찾고 싶다면
강아지, 고양이 class로 분류되는 이미지만을 가져오면 되는 것이다!
모델 학습
이제 준비된 데이터로 학습을 하면 된다.
Trainig dataset: label을 명확히 전달하여 모델이 공부할 수 있도록 주는 데이터이다.
Validation dataset: 모델이 잘 학습되었는지 중간중간 평가하면서 올바른 방향으로 이끌어주는 역할을 한다. training에 주지 않은 데이터셋이어야 한다.
위 그림에서처럼, 학습 초반에는 이미지 분류 성능이 좋지 않다. 아직 모델 학습이 덜 되었기에 제대로 분류하지 못하는 것이다.
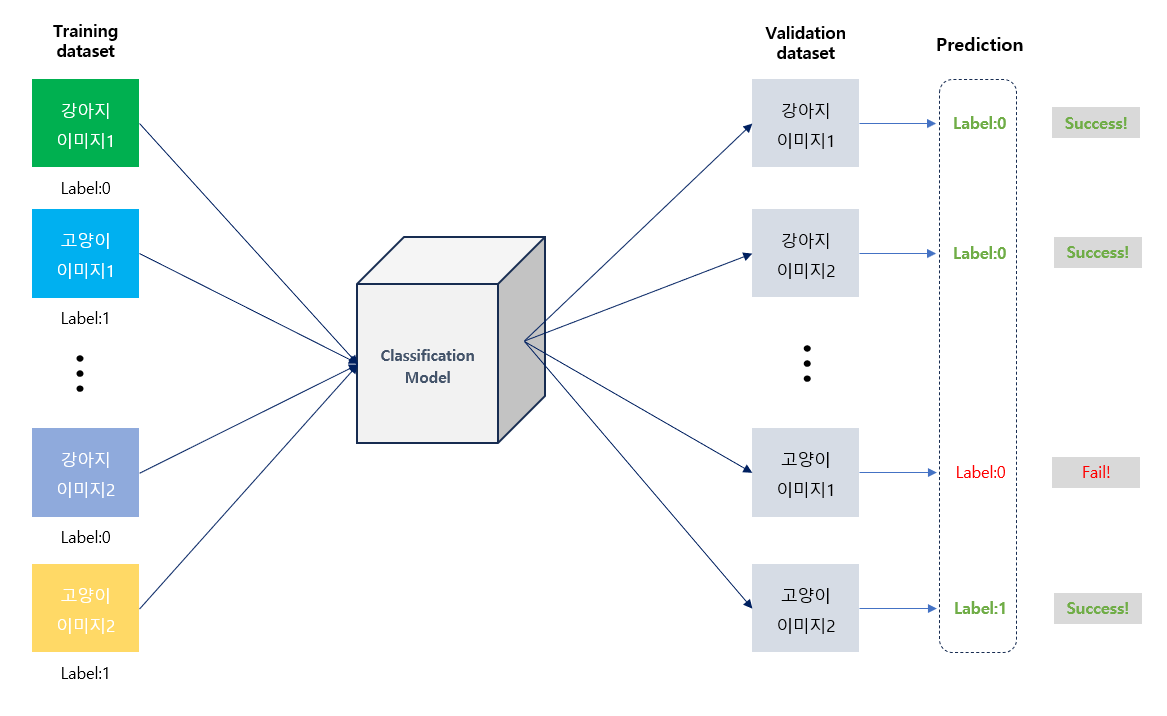
하지만 점차 학습 하다보면 이렇게 정답률이 높아지게 된다!
그렇다면, 모델은 이미지와 label을 이용해서 대체 어떻게 학습을 하는 것일까!!

이미지는 픽셀로 이루어져 있고, 각 픽셀은 숫자로 이루어져 있다.
인공지능은 우리가 보는 이미지가 아닌, 이 숫자를 통해 이미지를 바라보고 있다.
이렇게 숫자로 이루어진 이미지에서 특징을 찾는다.
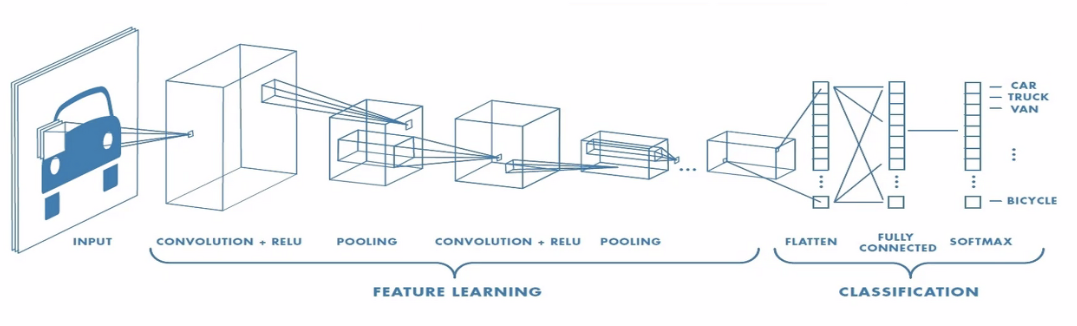
자세한 추출 과정은 생략하고 다음 포스팅에서 설명하겠다.
우리는 강아지/고양이 분류를 하기로 했으니,
강아지나 고양이의 이미지에서 각각의 특징을 추출한다고 보면 된다.
털의 색상, 털의 길이, 눈, 귀 등등의 특징을 나름대로 인공지능이 추출하게 된다.
그리고 추출된 특징을 가지고 분류를 한다!
결국 특징도 숫자를 나타내기 때문에 추출과정에서 특징적인 패턴을 발견하게 되는 것이고,
그 패턴을 압축! 압축! 한다.
결국 위 이미지처럼 하나의 vector만 남게되는 것이다.
(물론 이 과정은 달라질 수 있다. 대략적인 과정을 설명하고 있다.)
이제 여기서, loss의 개념이 등장한다.
추출된 특징이 긴 vector 형태로 나타났을 때 이것이 어떻게 분류까지 이어지는가?
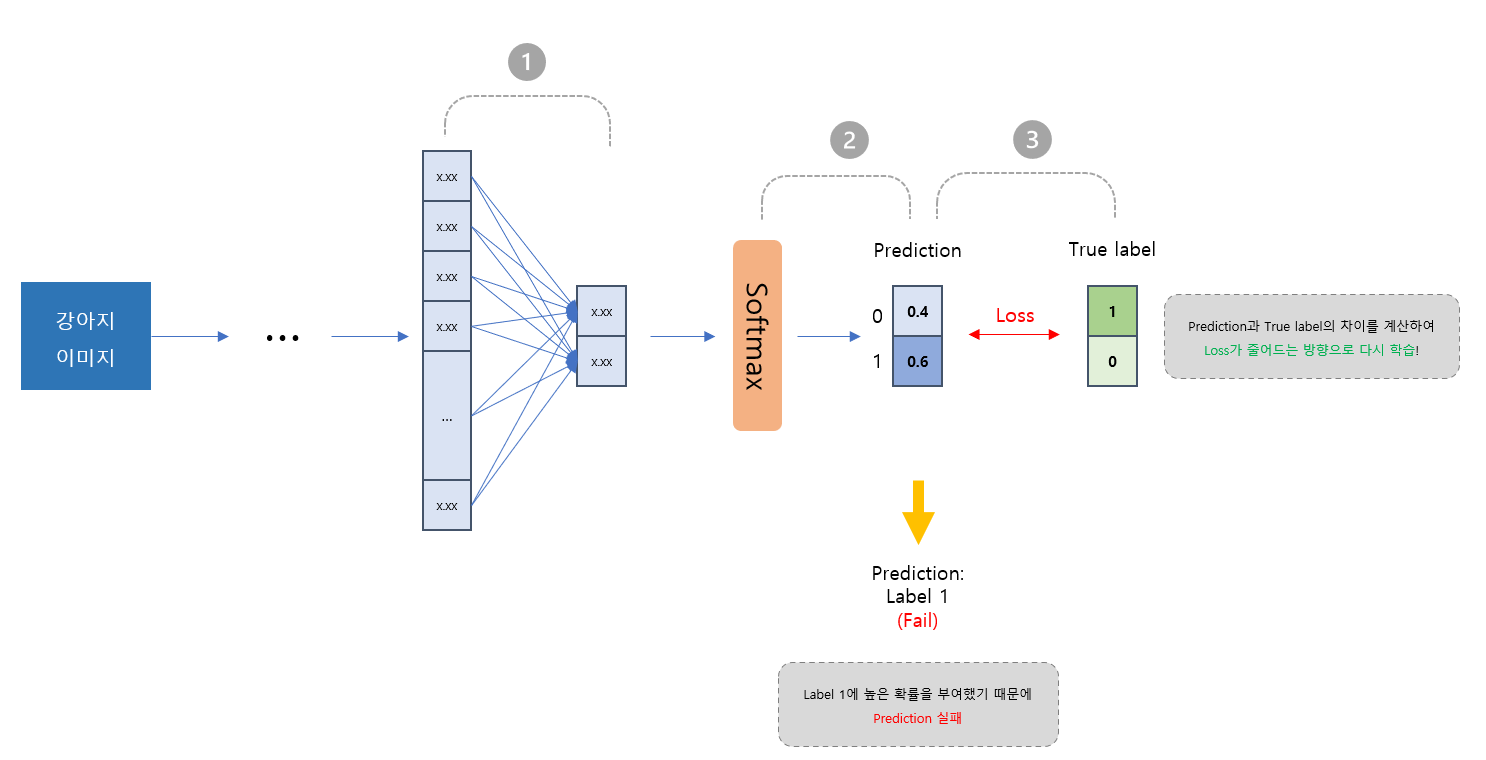
1. 먼저 긴 특징벡터를 label의 개수만큼 줄여주는 과정이 필요하다.
2. 이 후 Softmax 함수를 통해 확률화 해준다!
이 말은, 0과 1 중 어느 label일 확률이 더 높은 지를 측정하는 것이고 Prediction을 하는 것과 같다고 볼 수 있다.
이 이미지에서는 강아지(label은 0) 이미지가 들어왔지만 label 1의 확률이 더 높다는 예측을 했기에 예측에 실패하였다.
3. 그렇다면 이 후의 학습에서는 실패하지 않기 위해 Loss 계산을 해주어야 한다.
예측된 값과 실제 label의 차이를 구하고 그 차이가 줄어드는 방향으로 학습하게끔 도와준다.
여기까지 Image classification task의 전체적인 학습 과정에 대해 설명하였다.
batch, feature extraction, test pipeline.. 등등 아직 설명이 부족하지만.. 다음을 기약하며
쉽게 풀어서 쓰려다보니 더 자세한 내용은 많이 생략되었다. 이번 포스팅에서는 전체적인 흐름을 짚고 추후 딥러닝에 대한 자세한 이야기를 해봐야지!
'Deep learning' 카테고리의 다른 글
| 경량화: Pruning(가지치기) 기법 (2) | 2024.01.27 |
|---|
