Pruning 이란?
모델의 크기를 줄이고 계산량을 감소시키기 위해 불필요한 가중치 혹은 레이어를 제거하는 기법
Why pruning?
- Traning operations 감소: Pruning을 통해 일부 가중치 또는 연결이 제거되면 연산량이 감소하게 됩니다. 이로 인해 forward 및 backward 연산이 더 빠르게 수행될 수 있습니다.
- Training memory 감소: 제거된 가중치에 대한 메모리를 절약할 수 있습니다. 이는 GPU 메모리 사용량을 줄이고, 더 큰 배치 크기를 사용하거나 다른 복잡한 모델을 실험할 수 있게 해줍니다.
- Sparsity로 인한 Inference Acceleration: Pruning에 의해 희소한 모델이 만들어지면, 추론 시에 0에 해당하는 가중치들이 곱셈 연산에서 제외됩니다. 이로써 Sparsity를 활용하여 연산 속도를 향상시킬 수 있습니다.
- Inference memory 사용 감소: 희소한 모델은 메모리 사용량이 감소하므로, 추론 시에 메모리 효율이 향상될 수 있습니다.
Pruning Methods
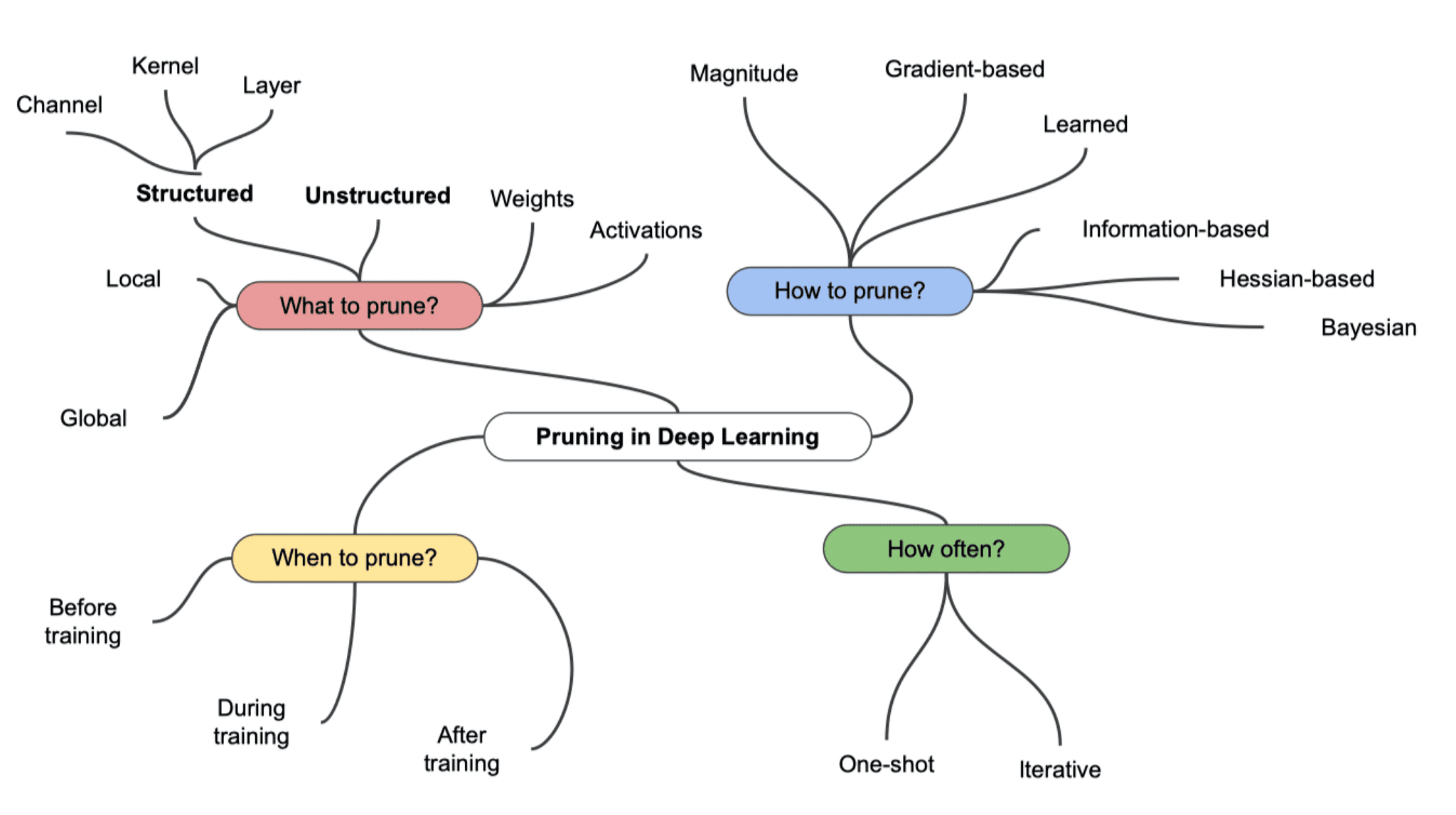
엄청나게 다양한 pruning 기법들이 있다.
📌 대표적인 pruning 기법
- L1 Regularization (L1 정규화):
L1 정규화는 모델의 손실 함수에 가중치의 L1 놈(norm)을 추가하여 가중치를 제한하는 방법입니다. 이를 통해 작은 가중치의 연결을 0으로 수렴시키고, 희소한 모델을 만들어 pruning 효과를 얻을 수 있습니다. - Global Magnitude-based Pruning:
전체 가중치의 절댓값에 대한 분포를 계산하고, 상위 또는 하위 퍼센트의 가중치를 제거하는 방법입니다. 예를 들어, 상위 20%의 가중치를 제거하면 상위 20%에 해당하는 가중치들이 가지치기되어 희소한 모델이 만들어집니다. - Layer-wise Magnitude-based Pruning:
각 층(layer)에 대해 가중치의 절댓값에 대한 분포를 계산하고, 각 층에서 상위 또는 하위 퍼센트의 가중치를 제거하는 방법입니다. 이는 각 층에 대해 개별적으로 pruning을 수행하므로, 모델의 각 부분이 서로 다른 pruning 비율을 가질 수 있습니다. - Iterative Magnitude-based Pruning:
여러 번의 pruning 반복(iteration)을 통해 점진적으로 가중치를 제거하는 방법입니다. pruning 후에 모델을 재학습하고, 이를 반복함으로써 점진적으로 희소한 모델을 형성합니다. - Structured Pruning:
특정 패턴이나 블록 단위로 pruning을 수행하는 방법입니다. 예를 들어, 컨볼루션 층에서 필터 전체를 제거하거나, RNN에서 특정 타임 스텝에 해당하는 연결을 제거하는 등이 있습니다. - Gradient-based Pruning:
역전파 도중에 그래디언트 정보를 기반으로 가중치를 업데이트하면서 pruning을 수행하는 방법입니다. 이 방식은 학습 도중에 동적으로 모델을 가지치기할 수 있는 장점이 있습니다. - Taylor Approximation-based Pruning:
Taylor 근사를 사용하여 각 가중치에 대한 미분 값을 계산하고, 미분 값이 낮은 가중치를 제거하는 방법입니다. 이는 모델의 출력에 미치는 영향이 적은 가중치를 제거하는 방식입니다.
Pruning example
아래는 내가 프로젝트에서 사용한 pruning 기법이다.
for name, module in model.backbone.named_modules():
# 모든 2D-conv 층의 20% 연결에 대해 가지치기 기법을 적용
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name='weight', amount=0.2)
# 모든 선형 층의 40% 연결에 대해 가지치기 기법을 적용
elif isinstance(module, torch.nn.Linear):
prune.l1_unstructured(module, name='weight', amount=0.4)HRNet의 백본에서 Conv2d(2D 컨볼루션) 층에 대해서는 20%의 가중치를 제거하고, 선형(Linear) 층에 대해서는 40%의 가중치를 제거하는 L1 가중치 가지치기(pruning)를 수행하였다.
- 각 가중치 행렬의 원소에 대한 L1 놈을 계산
- 계산된 L1 놈을 바탕으로, 특정 비율(amount)만큼의 가중치를 제거
- 가중치가 일부 제거된 상태에서 모델을 학습
➡️ 모델의 일부를 희소(sparse)하게 만들어 모델을 가볍게(경량화) 만들 수 있다.
이 결과, inference time이 약 10% 감소하였다!
'Deep learning' 카테고리의 다른 글
| 아주 쉽게 이해하는 Image Classification (1) | 2024.01.29 |
|---|
